- Have any questions?
- +91 9176206235
- info@phdsupport.org
PhD in Reinforcement V2V Communication in 5G Network

PhD in Performance Evaluation LTE Handover in 5G
May 26, 2021PhD in Optical Communication Using Machine Learning
May 26, 2021
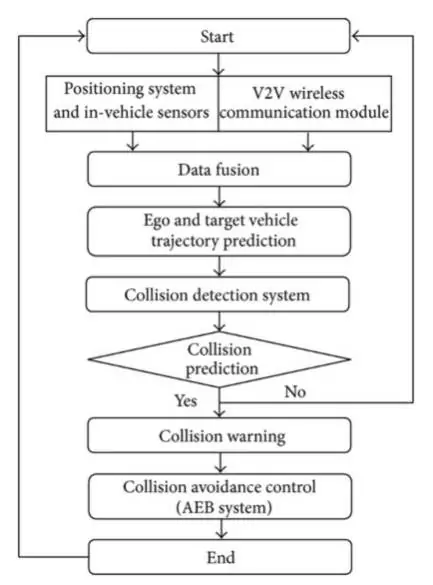
Proposed Solution
The 3GPP initiated sidelinking to take a vital technical basis in handling both basic and advanced safety cases. The Physical sidelink feedback channel carries a Hybrid automatic repeat request from a recipient vehicle of a message which is in either of the two forms. Then to reduce the input dimension types of drivers’ dangerous behavior are enlisted as it is the key factor for crashing.
The problem formulated can be denoted as:
![]()
As per the proposed reinforcement learning based V2V communication using 5G Network, a variant of the 0-1 knapsack problem offers to increase the reward while maintaining the cost under a certain threshold level.
The equation for determining the optimal is written as follows:
![]()
Future Proposal
The future proposal can be regarding the “relaxation” of the regression of the behavior of the vehicle’s driver. This will be based on the proposed reinforcement learning based V2V communication using 5G Network.
Our Experts provide complete guidance for PhD in Reinforcement Learning based V2X communication using 5G Network.
Phd in reinforcement learning v2V communication using 5g network coding implementation support & Paper writing and Publication support. We do support matlab simulation for coding implementation Phd in reinforcement learning v2x communication using 5g network.

{kind=link}